






Could a polymorphic memory resource (PMR) improve last weeks results?
published at 31.03.2023 17:28 by Jens Weller
Save to Instapaper Pocket
I've been wondering if there is another easy way to improve performance of last weeks post on using boyer_moore_horspool search for replacing strings.
Last weeks code actually does not need to reallocate the string when doing replacements, so its in that way a bit more efficient then a good test should be. I've implemented a search-pattern-first and then replace method, but this runs slower due to having to handle the allocations for the position data and searching the string one more time for the replacements.
Also, I run and write this code on quick-bench.com, which has its limitations in what is available.
Which got me thinking: what could be improved outside of a different algorithmic approach? And so Marek Krajewskis talk from Meeting C++ 2022 "Basic PMRs for improving performance" suddenly had my attention. I've heard about PMRs as a C++17 feature, and what you could do with them. So, turning heap allocations into a stack based memory should bring success, right?
Well, its not so easy this time as I figured out. I strongly recommend you watching Mareks talk for a good overview on this C++17 feature.
Before I watched Mareks talk about PMR, I looked at cppreference, especially interested in pmr::string/vector. While there were some interesting types present, it was missing these. It turns out, that these are templated typedefs present in their header of which ever class/container you'd like to use with the polymorphic memory resource. After all, the only change is in the allocator.
With this new type of allocator and various ways to create a memory pool, PMR is an interesting tool to look for performance improvements. Especially when you have functions or classes creating strings or containers that are enclosed within these. Afterall you want the allocator and the stack memory potentially holding your datatypes to outlive the containers.
Results
When I first plugged in the PMR string/vector types with a memory resource the first results seemed to clearly show an advantage. And its not so hard to argue for this, its going to be what you may expect. But then I realized, that I shouldn't compare last weeks result against the new code. Also running the same code on quick bench gives a variation of timings.
Then, my code isn't the best to measure the PMR effect. While the string gets newly created and copied every loop, one can expect that its not a new allocation with every iteration. And with that, the cost of this allocation is not really what makes a difference. Which mostly leaves us with cache effeciency.
Some of my experiments resulted in being slightly slower or faster, but within a certain error margin. Twice I've hit a combination of code which gave me a 1.1 or 1.2 speedup, but then always finding out that the other code should run in the same way regarding allocation. And this led to my code being again as fast as the original solution. So I needed to tweak the code to be not as cache friendly as last weeks code is. In the previous weeks I've always used a vector which then is rotating through its elements in the test loop. Also in this code I ditched the other two solutions, as they are slower. And this time, its clear to see that PMRs can bring an improvement.
static void StringReplaceBMHPMR(benchmark::State& state) {
//char buffer[2048] = {}; // a small buffer on the stack
std::pmr::monotonic_buffer_resource res;//{std::data(buffer),std::size(buffer)};
std::pmr::unsynchronized_pool_resource pool{&res};
std::pmr::string s{"Hello ${name}, test text is ${test}, ${num},${num},more text",&pool},
a{"Hello ${name}, more text is ${test}, ${num},${num},more text",&pool},b{"Hello ${name}, more text is long very long, long long text ${test}, ${num},${num},more text",&pool},
p{"Hello ${name}, test text is long ${num} text ${test}, ${num},more text",&pool};
std::pmr::vector< std::pmr::string> v{&pool};
v.push_back(a);v.push_back(s);v.push_back(p);v.push_back(b);
size_t i =0;
....
for (auto _ : state) {
std::pmr::string copy = v[i%v.size()];
...
Using the local mem array for the monotinic_buffer_resource will make the advantage disappear.
The result:
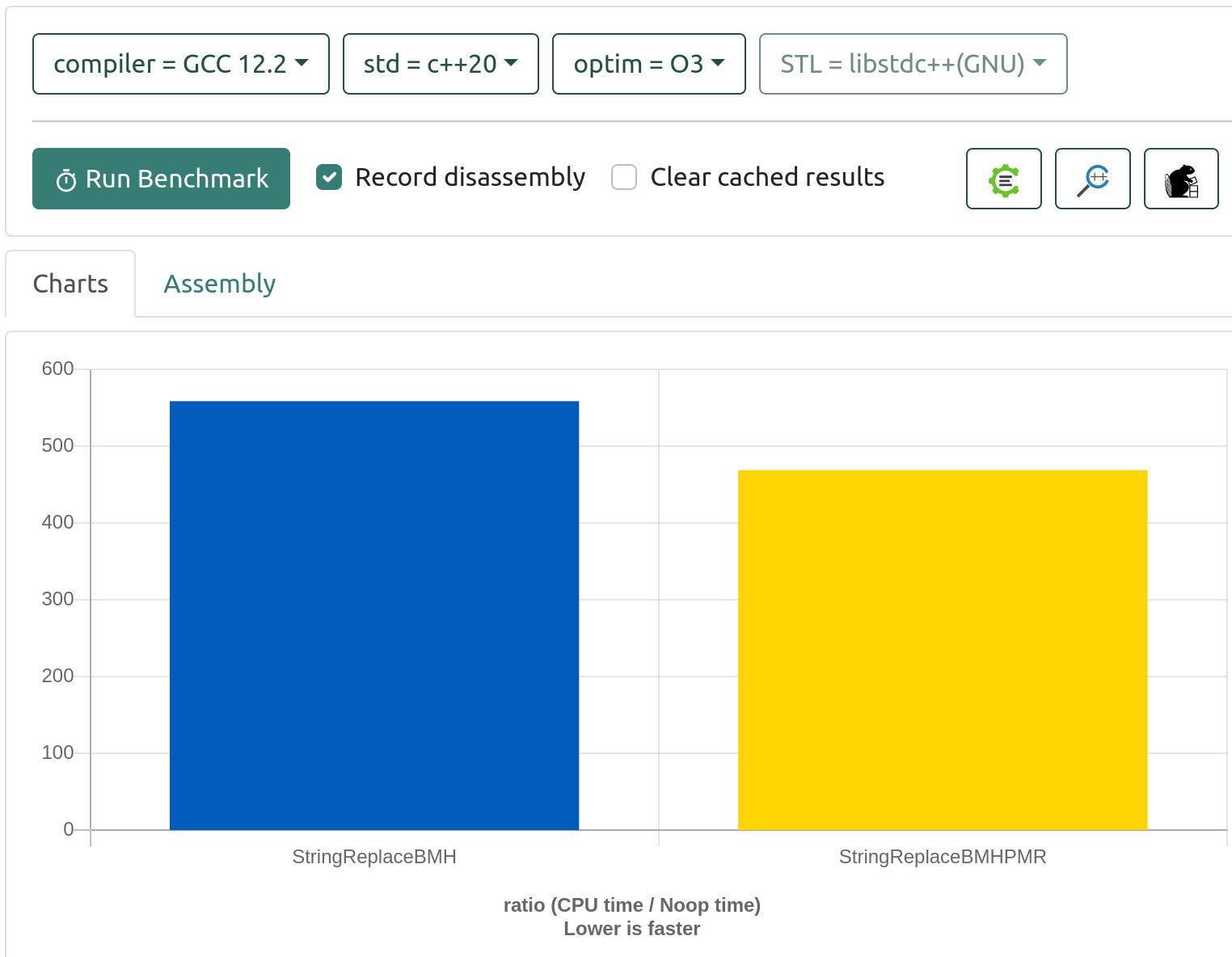
Though as some of this is cache driven, one never knows how this is influenced by other processes running in quick-benchs cloud env. One trend I've seen is that more tests make a certain test run a bit longer on quick bench.
What I learned from playing around with this for a few hours: PMR is a great tool to make better use of your resources regarding allocations and cache access. Though my code example isn't the best to demonstrate this IMHO. Its string and container typedefs can be of great help to make local access faster. Though that these are typedefs makes it at the beginning hard to find actual information on them. You kind of expect them to show up in the headers documentation (like std::pmr::string/vector), or mentioned/linked in the examples and pages for the various classes in CppReference. But this is sparce, and only when looking up the base type you'll find the typedef.
And typedef has a second consequence: a function taking an std::string does not take a std::pmr::string. As the allocator is different they are different types. If your interfaces are templated and take basic strings with templated allocators you may not be affected. But refactoring a local std::string or container to its pmr type will show you where you've got to update your interfaces. If you'd like to share the data with the outside world, this may force you to copy your local variables into the callers version. Sometimes that will be worth the tradeoff, to have a fast loading and parsing of a file or a long and difficult calculation run on local memory and then copy the results. But you should be aware that this may be needed and if overlooked can cause errors.
Which is I think the biggest pit fall with pmr: like string_view the memory may not be owned by the type. The allocator needs to outlive its allocations. So when introducing pmrs to your code base, maybe watch Marek Krajewskis talk with your team, so that folks know the various use cases and how pmr types work.
Last but not least I want to thank Marek Krajewski for submitting and giving the talk. I'd like to see more folks give talks based on their experience, even if its a 5 year old feature. Experience needs time to build, and to some of us talks on features that are actually available to our code bases are more interesting then the newest feature of C++2x.
Join the Meeting C++ patreon community!
This and other posts on Meeting C++ are enabled by my supporters on patreon!