






Comparing accumulate to C++23s fold_left
published at 13.10.2025 21:34 by Jens Weller
Save to Instapaper Pocket
Recently I've used accumulate to sum up the t-shirt sizes for Meeting C++ 2025, and wondered if there as a ranges version I could use.
And there is fold_left in ranges, while functions like accumulate from the header are not yet covered by ranges. An alternative can also be std::reduce, which is already in C++17 and also has parallel algorithms covered. But a simple map<String,int> with t-shirt sizes does not benefit from parallel processing. Also its the value part that I'd like to add up. Anyways, if you want to read up on fold_left, fold_right and more, Sy Brand wrote a great article about these functions. Also, accumulate and fold_left have the same interface, except that one ranges version takes not an iterator pair but the container it self.
So while my code is not really in need to get faster, I was curious about comparing the ranges version with fold_left to accumulate. There should not be any difference. So I was surprised to see that there seemed to be one. When I was done with my test code on quick bench, the result was that fold_left was 1.1 times slower then accumulate. This could be simply because quick bench offers GCC 13.2 which has support for fold_left, but not more up to date versions of GCC. Clang does not yet support fold_left on quick bench either, and my own code also is on GCC 13 so far.
The next thing I did was to add the iterator version of fold_left to my tests, to see if it would be consistent in speed with either algorithm. I've been motivated also by wondering if something with handing over the whole container vs. iterator only was causing this. The resulting tests showed that only fold_left with the container given was slower:
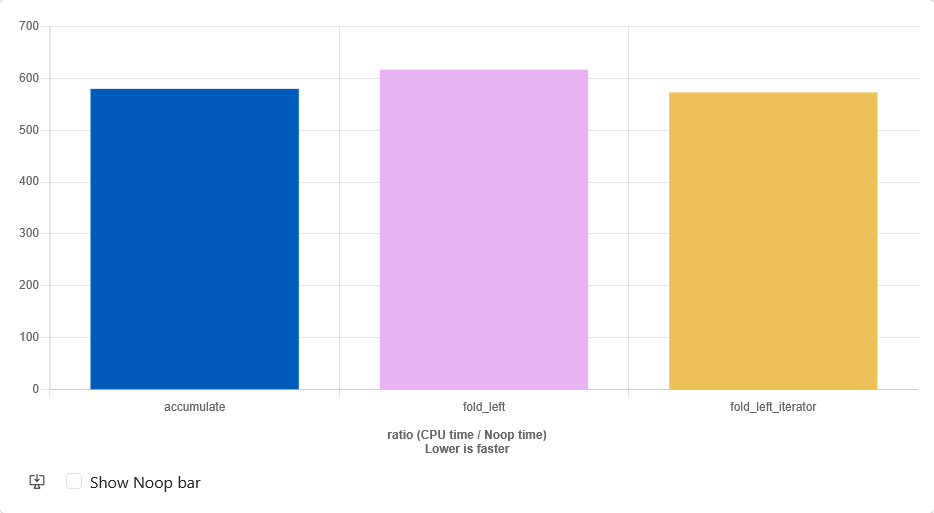
Case closed? There was a recent entry from Daniel Lemires that also showed that ranges code can be slower. Though I've seen a reply to this showing that this wasn't true using quick-bench. So the codes performance was depending on which platform you'd be running it, which in Lemires case was apple clang. Which motivated me to look closer into this.
Unfortunately there is no other platform I can test the code on quick bench, clang does not have or find fold_left. But I noticed that quick bench defaultet for me to O3 als optimization level. Which got me curious. When changing to O2 I get this result:
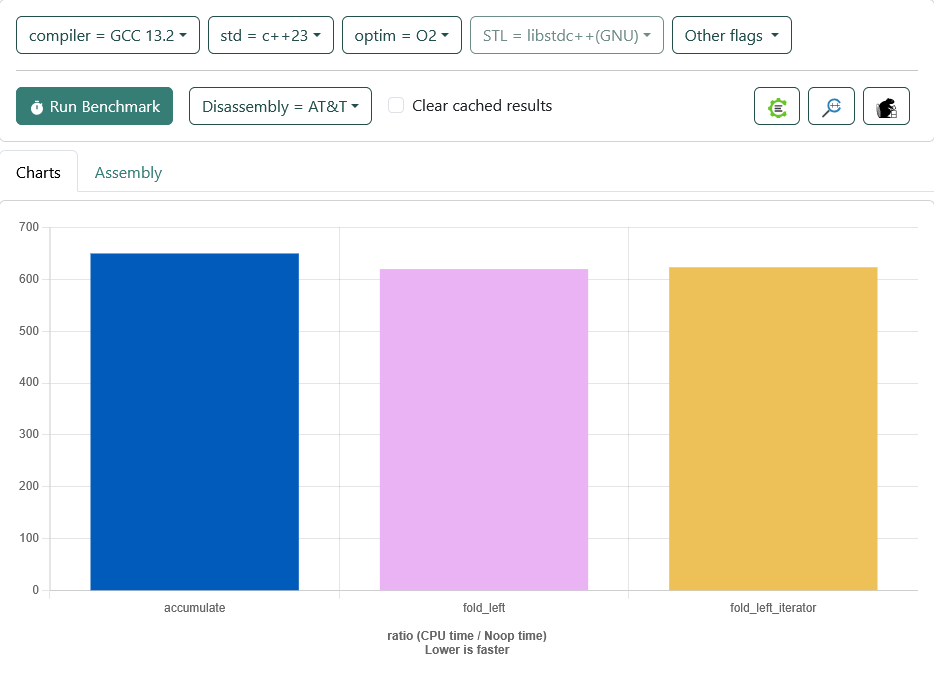
Suddenly fold_left is 1.1 faster than accumulate. And sometimes ranges algorithms or newer standard types might have the advantage of being more modern or a better alternative on some platforms. Like shared_mutex is smaller then std::mutex under windwos due to ABI constraints. Though I don't really expect this in this case to be an option here. Measuring with O1 even shows the second test with the container instead of iterators to be winning, again by a factor of 1.1:
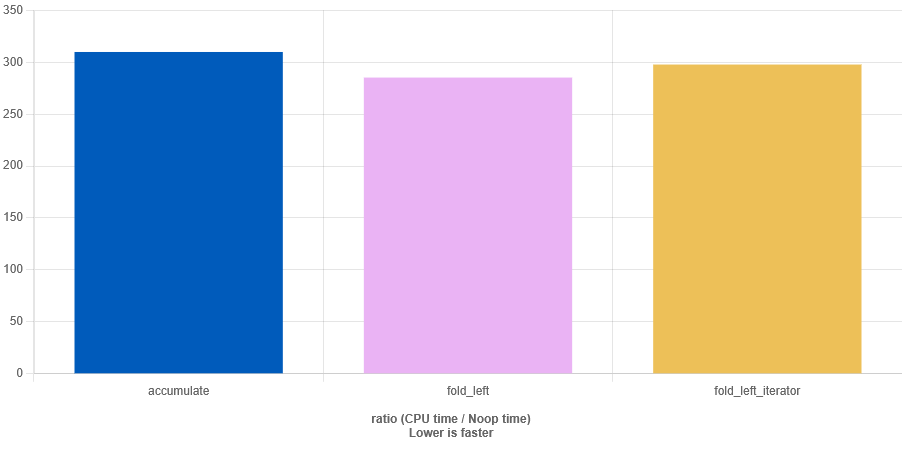
While a factor of 1.1 sounds small, it actually means a 10% difference. If we add up O1/2/3 the result evens out, but I've been rerunning the tests on O1,O2 and O.3 and the pattern stays. I've doubled the map and results don't change much either. Interestingly I've not been able to have them perform all the same. On O3 the iterator version of fold_left is as fast as accumulate, otherwise its as fast as fold_left with the container argument.
My gut feeling was that these are the same speed, which I still think should hold true. Asking folks on LinkedIn if fold_left is slower (41%), equal(26%) or faster (32%) than accumulate showed that there is no real consensus.
Thanks for reading that far. Writing to this point made me wonder if there was something in the code it self.
int sum = std::accumulate(s.begin(),s.end(),0,[](const auto& sum, const auto pair){return sum + pair.second;});
//or
int sum = std::ranges::fold_left(s.begin(),s.end(),0,[](const auto& sum, const auto pair){return sum + pair.second;});
And indeed there is a small oversight. But I think that makes it worth sharing even more. All the code above does the same, but the lambda takes the second value by value, and not by reference. This causes a copy, and seems the root of this behavior. When the reference is added, my gut feeling is correct, they are all the same:
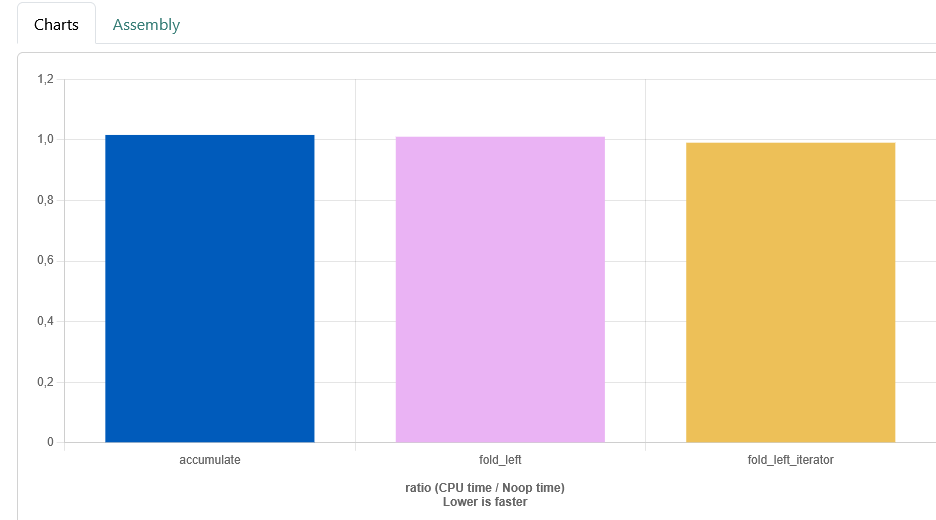
On all optimization levels.
Except O1. Than the container ranges version is slower again. In all versions all 3 test run the same arguments, so there is no mix up between a callback with references and one with out for the second parameter. I wonder if there are some cache effects which cause this, does the order of tests have an influence on this? At least if that is the case, a reordering of the test cases should have an effect. And indeed moving the iterator version of the fold_left algorithm to be the first test results in fold_left being fastest as last test added. Case closed. At least for now...
Join the Meeting C++ patreon community!
This and other posts on Meeting C++ are enabled by my supporters on patreon!