






Comparing a pool allocator based unique_ptr and direct access to a type in a vector
published at 28.03.2024 17:10 by Jens Weller
Save to Instapaper Pocket
My last blog post dealt with a possible solution to providing a stable memory address. Some of the feedback pointed towards arena/pool allocators to be used instead.
And its true, yes such an allocator can provide the needed stable memory address. It would be also the right solution if that would fit my requirements. If it would be important to the design of the library, and the performance critical parts of the code would have this reflected in their design. Arena / pool allocators are great when one wants to cut down on allocation costs, as they can offer a way to not have a heap allocation everytime you use unique_ptr.
Though my use case is different, most allocations are stable and there is not much of a benefit in hosting objects in pool allocations instead of having them directly in the container. What I need is a stable address for the UI, Qt. Most of this will be in a part where the loss of performance through an indirection is acceptable for me. When displaying a table view with a million lines one should choose a different strategy. Though the performance critical part of my code can in my solution access the objects in memory and does not get to access its data through a handle like unique_ptr. Having my elements in a vector will always ensure that they are directly in memory and access should be cache friendly. So the performance should be better, with the tradeoff that the objects need to host the mechanism which provides the stable address to them while they move around in memory.
But of course I should measure that. After all a pool allocator places the elements close to memory in the same block. How much of a gain is it to not have this indirection to a memory block? While elements are removed sometimes, its not going to be a big factor. I opted for simulating this by having n% (I've tested between 2 and 50%) of the objects also be allocated to a different vector for the pool code. That way there is some gaps in memory which with this would naturally occur through deletions or allocations for elements not accessed in the current code. For elements directly in a vector this will not play a role, as removing an object will move the next objects back by one in their positions.
I've written a memory pool in the past for unique_ptr, so this design will be similar. Back then the design goal was to share a resource, to create an object which is expensive and share then n instances accross threads. This time its a more general solution, but for simplicity the pool only supports one type. The focus is on testing the memory access to see if a more versatile implementation would make sense to have a pool allocator serve various object types of different sizes.
This is why I kept the pool page class rather simple
ttemplate< class T, std::size_t size>
class PoolPage
{
std::array or vector< T,size> elements;
std::vector< T*> freelist;
std::size_t free_index = 0;
public:
using del_t = std::function<void(T*)>;
using ret_ptr = std::unique_ptr<T,del_t>;
PoolPage(){}
PoolPage(PoolPage&& m):elements(std::move(m.elements)),freelist(std::move(m.freelist)),free_index(m.free_index){}
PoolPage& operator=(PoolPage&& m)
{
elements = std::move(m.elements);
freelist = std::move(m.freelist);
free_index = m.free_index;
return *this;
}
PoolPage(const PoolPage&)=delete;
PoolPage& operator=(PoolPage&) = delete;
ret_ptr getInstance()
{
auto del = [this](T* p){freeInstance(p);};
if(freelist.size() > 0)
{
T* t = freelist.back();
freelist.pop_back();
return ret_ptr{t,del};
}
if(free_index < elements.size())
return ret_ptr{&elements[free_index++],del};
auto nulldel = [](T*){};
return ret_ptr{nullptr,nulldel};
}
bool has_space()const
{
return freelist.size()>0 || free_index < elements.size();
}
void freeInstance(T* t)
{
auto it = std::find_if(elements.begin(),elements.end(),[this,&t](T& ref){return &ref == t;});
if(it != elements.end())
{
freelist.push_back(t);
}
}
};
At the moment this code is only used to allocate objects, the freeing of the resources doesn't come to play and at the moment is not really implemented. There would be various strategies for both construction and freeing of an instance, but this is not what I want to test. I've originally chosen std::array for holding the memory of the pool, then there is a vector of T* and an index for which part of the pool page is filled. If you make the type move only, the std::array needs to replaced with a vector, as the array is not able to move its actual memory along.
The pool class then holds this in a vector. When the PoolPage uses an std::array, then the pool has to wrap the page in a unique_ptr, with a vector and the PoolPage made move-only, it can be the element itself in the vector (e.g. vector<PoolPage>). Both way you do create an allocation, either a unique_ptr holding the PoolPage or the vector allocating its memory block. When measuring access, I could not find a difference between the two approaches.
The Pool class then simply only has to manage the pages and return an allocated object. The pool page is already doing most of the management.
template< class T, std::size_t page_size = 50>
class Pool
{
public:
using page_t = PoolPage< T,page_size>;
using ptr_t = page_t;
page_t::ret_ptr getInstance()
{
for(auto& page: pool)
{
if(page.has_space())
return page.getInstance();
}
pool.push_back(page_t{});
return pool.back().getInstance();
}
private:
std::vector< PoolPage> pool;
};
I've measured with small and big page sizes, not seeing a difference in the numbers. The getInstance method returns a unique_ptr with a custom deleter, which returns the allocation space to the pool and adds this object to the freelist. This is not an implementation of a standard allocator which could be used directly on the vector. If you do this, the behavoir of the vector will again break your stable memory address.
With this the basic setup is done. These types are kept simple, one could add mutexes and other things to make this thread safe, but this is a different story.
I wanted to keep the test classes also simple, one needs to be a bit bigger to account for the extra space the mechanism of my stable memory implementation would take up:
struct AB
{
int a=1,b=2,c=3,d=4;
size_t sum;
std::array< char,32> arr;
};
struct ABC
{
int a=1,b=2,c=3,d=4;
size_t sum;
std::array< char,64> arr;
};
In the beginning I've started with the same type, and it was already faster. But I wanted this to be a bit more realistic, after all my solution does add a member variable to the types, and so making them bigger in memory footprint. For this I've added 32 bytes - which is likely more then what adding my mechanism would take up.
The test blocks do similar things.
static void regular_access(benchmark::State& state) {
std::vector< ABC> vec;
for(size_t i = 0; i < 100; ++i)
vec.emplace_back(ABC{});
// Code before the loop is not measured
for (auto _ : state) {
size_t sum = 0;
for(auto& val:vec)
{
sum += val.a + val.c;
val.sum = sum;
}
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(sum);
benchmark::DoNotOptimize(vec);
}
}
BENCHMARK(regular_access);
static void unique_ptr_pool_access(benchmark::State& state) {
Pool< AB> ab_pool;
std::vector<Pool< AB>::page_t::ret_ptr> vec,v2;
for(size_t i = 0; i < 100; ++i)
{
vec.emplace_back(ab_pool.getInstance());
if(i%50 ==0)
v2.emplace_back(ab_pool.getInstance());
}
// Code inside this loop is measured repeatedly
for (auto _ : state) {
size_t sum = 0;
for(auto& val:vec)
{
sum += val->a + val->c;
val->sum= sum;
}
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(sum);
benchmark::DoNotOptimize(vec);
benchmark::DoNotOptimize(v2);
}
}
// Register the function as a benchmark
BENCHMARK(unique_ptr_pool_access);
Both times a vector with the types is created, for the pool code I've created a second vector to be able to simulate allocations being freed or taken up by other objects in the pool. Though making this rare with i % 50 did not improve things for the pool code. Adding a write to the array makes the direct memory access a bit better.
The result
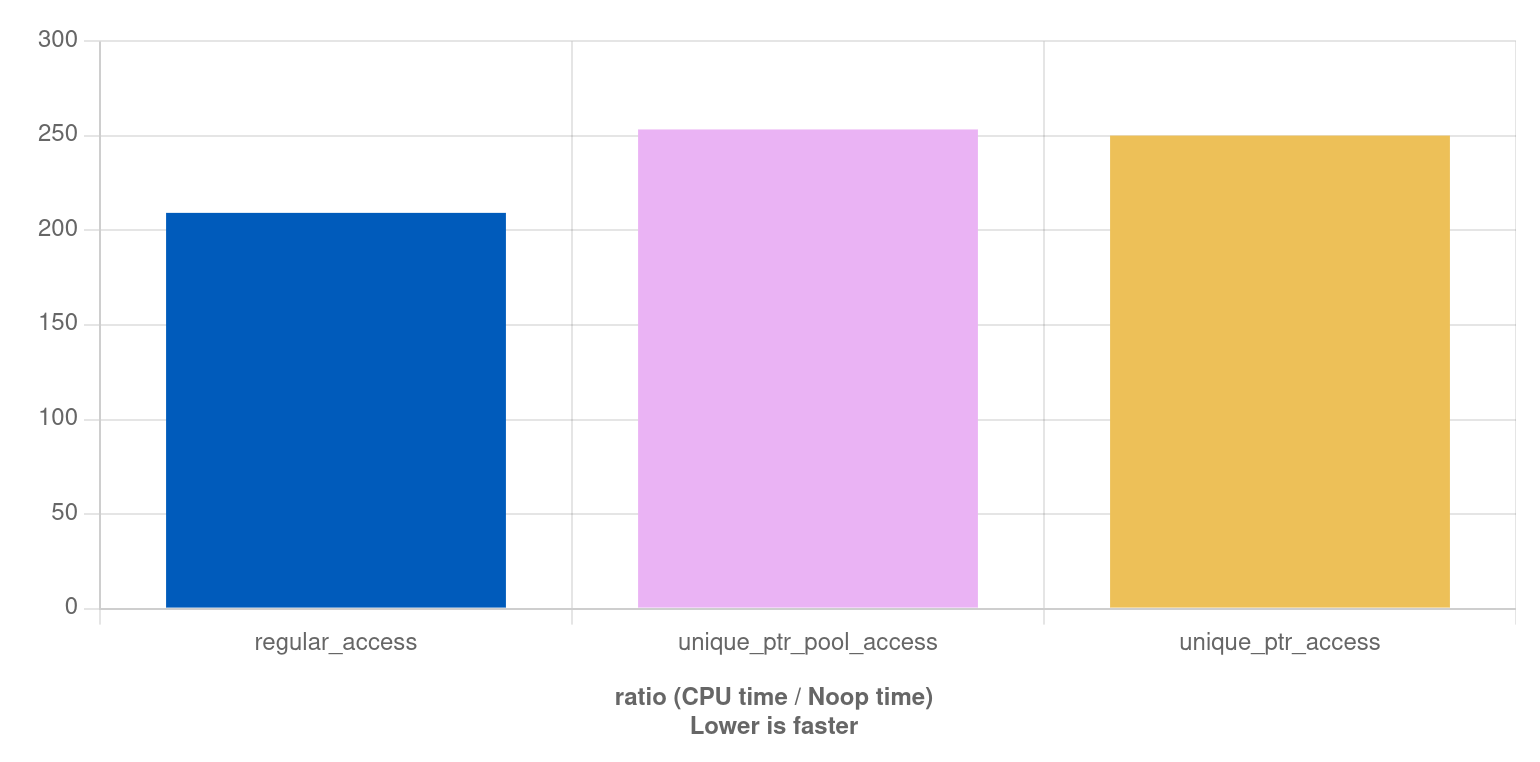
A link to the code for this result. I've been playing around with various changes, increased the ABC type and added the comparison to a normal unique_ptr. Unless you increase the ABC size to a lot more bytes then AB, the direct access in the vector is faster by a factor of 1.2. This even holds when making ABC 200 bytes larger then AB. Though that adding an indirection to memory access is slower isn't really surprising.
But have in mind that my solution for a stable memory address is not meant as a replacement for an arena or pool allocator! It just shows that other solutions exist, which can lead to making the code for other clients of the class faster. I've added the unique_ptr test to see if a pool would be faster than using the system allocator with new and heap allocation. Though to explore that, I'd have to measure if the pool allocator is doing better with alloc/dealloc then the system one used in make_unique.
Also you have to know which trade offs are possible in the design of your code. Adding the cost of a second small allocation is acceptable in my use cases. Its a one time cost, while wrapping your types in handles to an allocation will have a small cost each time you access this object.
Join the Meeting C++ patreon community!
This and other posts on Meeting C++ are enabled by my supporters on patreon!